C语言入门及进阶



\t 制表符 与 空格的关系
https://www.cnblogs.com/guokai/p/3641953.html
tab
如何 在 C 输出 \ %
%% \ \
如何在 C使用 百分数 %
double n,x;
n=0.01*x;
2.各种类型输入输出

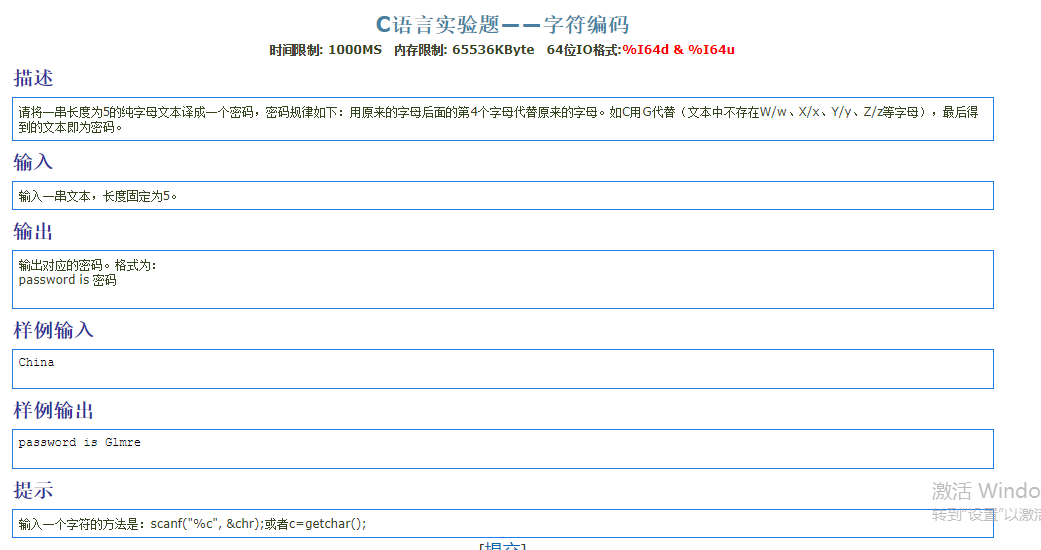
1 | 特别注意 A-Z区间的表示 以及 字符的 '' |
1 |
|
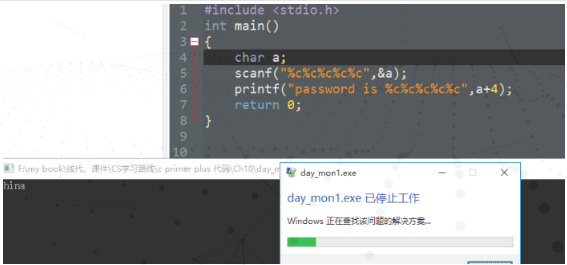
这种 不行 会报错

1 |
|
3.简单运算
1 |
|
4.加点难度的运算

1 |
|

1 |
|
1 |
|
5.简单选择结构

1 |
|

1 |
|
三目运算符
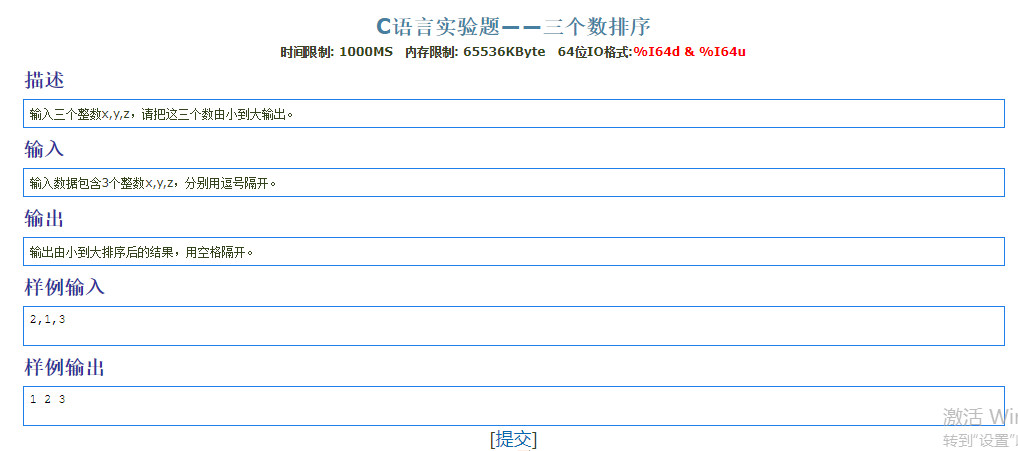
三数比较
1 |
|
二数比较
1 |
|

1 |
|

1 |
|
1 |
|
6.加强选择结构

1 |
|

1 |
|
强调 实数的定义 数学知识的补充 课外知识的背景 还有 学好英语!!!!!
上面挖个坑 你把函数 指针 学熟 再来补
1 |
|
1 |
|

1 |
|
7.简单一重循环

1 |
|
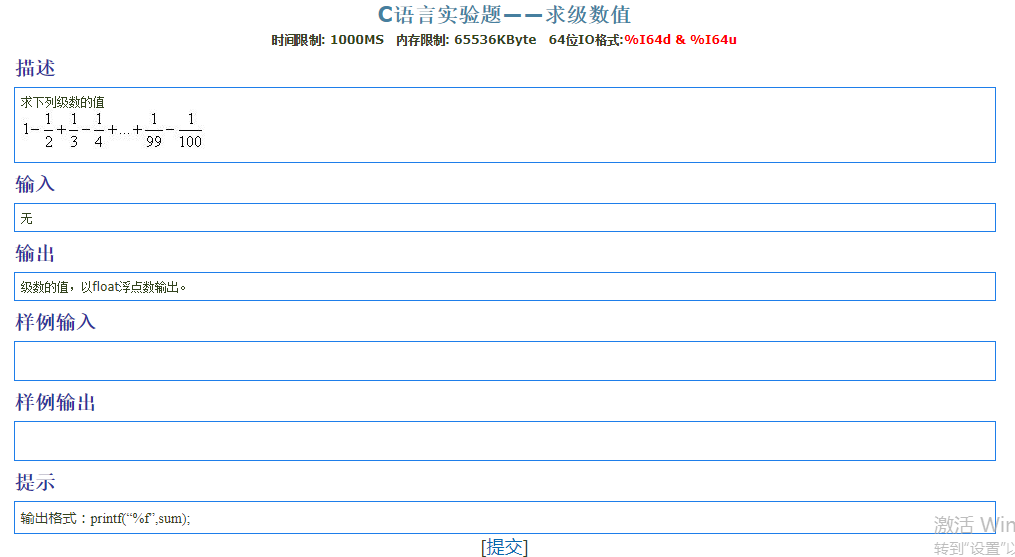
1 |
|
1.0 的重要性
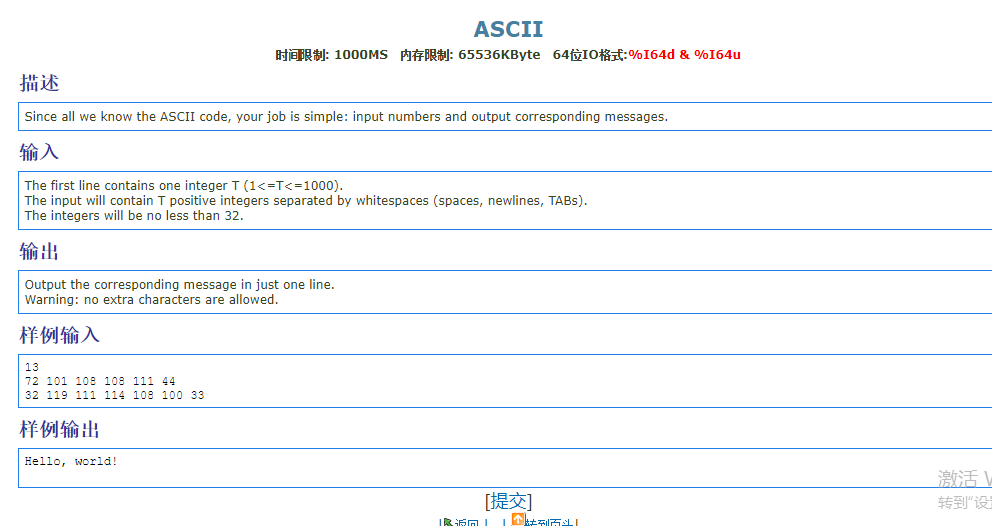
1 |
|
https://www.cnblogs.com/kimsimple/p/6874988.html
#include<bits/stdc++.h>包含了目前c++所包含的所有头文件

1 |
|
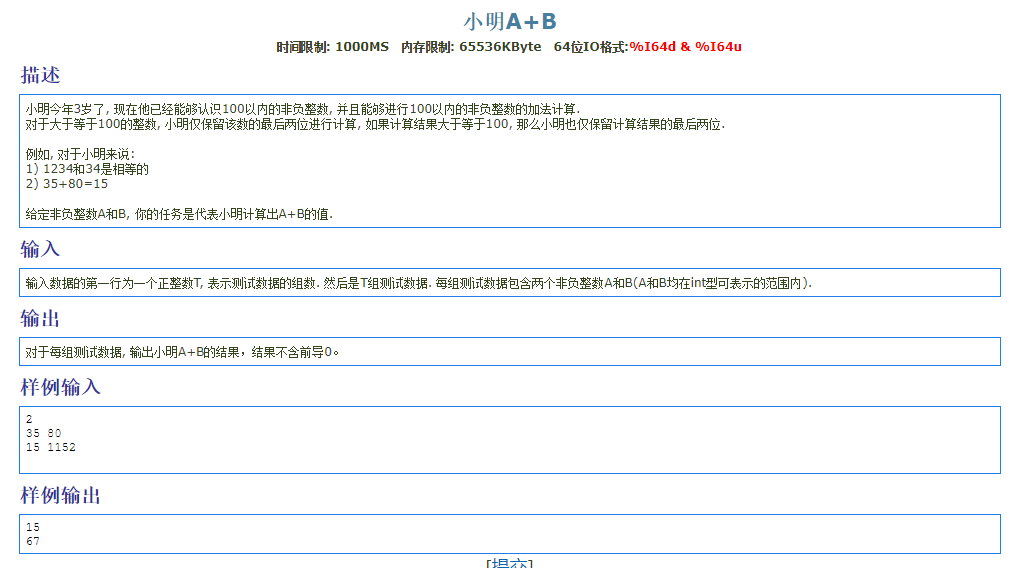
1 |
|
关于while(n–)知识点的补充
下面这段代码我们都很熟悉
#include <stdio.h>
int main()
{
int n=5;
while(n)
{
n=n-1;
}
printf(“%d\n”,n);
return 0;
}
它的输出结果为0.
再看下面这一段代码:
#include <stdio.h>
int main()
{
int n=5;
while(n–)
{
;
}
printf(“%d\n”,n);
return 0;
}
它的输出结果却是-1.
很多人都认为这两段代码是等价的,我之前也误认为它们等价,但是实验证明这不是等价的。
第二段代码中,while(n–),当n=0时,并没有马上跳过循环条件和循环体,而是将循环条件执行完再跳过循环体。
原因:n–是一个整体,从编译器gcc角度看,先将n赋值给一个临时变量,然后自身减去1,返回的不是n而是临时变量。此时临时变量0,n为-1。故n–操作是一个整体,必须完整的执行完,不是割裂看的。之前,我误认为while中判断n为0时就直接结束。

1 |
|
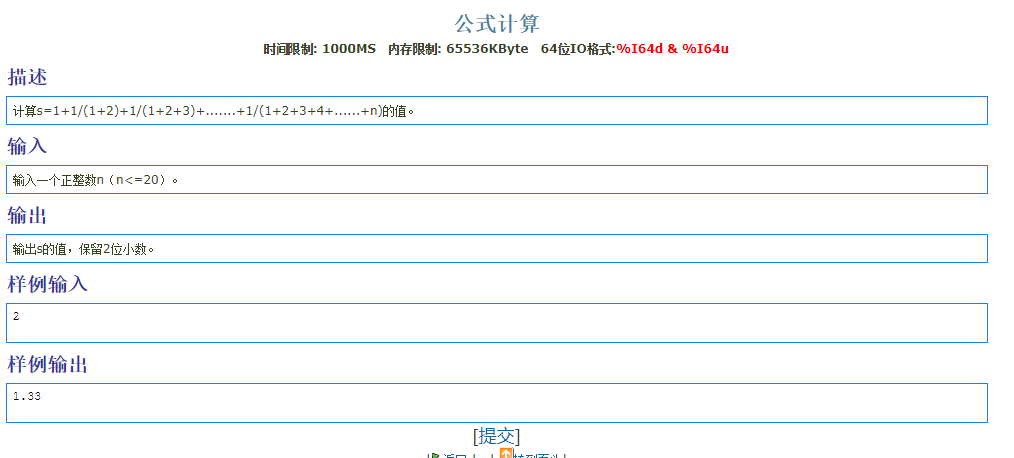
1 |
|
论 sum=0的重要性
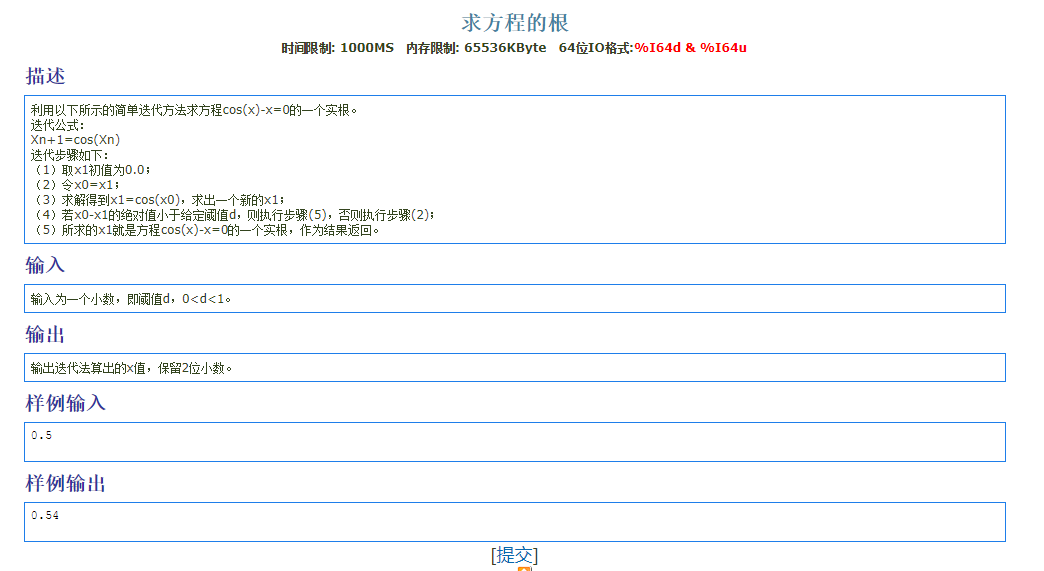
1 |
|
迭代
迭代法是数值计算中一类典型方法,应用于方程求根,方程组求解,矩阵求特征值等方面。其基本思想是逐次逼近,先取一个粗糙的近似值,然后用同一个递推公式,反复校正此初值,直至达到预定精度要求为止。
从概念上讲,递归就是指程序调用自身的编程思想,即一个函数调用本身;迭代是利用已知的变量值,根据递推公式不断演进得到变量新值得编程思想。
从直观上讲,递归是将大问题化为相同结构的小问题,从待求解的问题出发,一直分解到已经已知答案的最小问题为止,然后再逐级返回,从而得到大问题的解(一个非常形象的例子就是分类回归树 classification and regression tree,从root出发,先将root分解为另一个(root,sub-tree),就这样一直分解,直到遇到leafs后逐层返回);而迭代则是从已知值出发,通过递推式,不断更新变量新值,一直到能够解决要求的问题为止。
递归实际上不断地深层调用函数,直到函数有返回才会逐层的返回,因此,递归涉及到运行时的堆栈开销(参数必须压入堆栈保存,直到该层函数调用返回为止),所以有可能导致堆栈溢出的错误;但是递归编程所体现的思想正是人们追求简洁、将问题交给计算机,以及将大问题分解为相同小问题从而解决大问题的动机。
迭代大部分时候需要人为的对问题进行剖析,将问题转变为一次次的迭代来逼近答案。迭代不像递归一样对堆栈有一定的要求,另外一旦问题剖析完毕,就可以很容易的通过循环加以实现。迭代的效率高,但却不太容易理解,当遇到数据结构的设计时,比如图‘表、二叉树、网格等问题时,使用就比较困难,而是用递归就能省掉人工思考解法的过程,只需要不断的将问题分解直到返回就可以了。
总之,递归算法从思想上更加贴近人们处理问题的思路,而且所处的思想层级算是高层(神),而迭代则更加偏向于底层(人),所以从执行效率上来讲,底层(迭代)往往比高层(递归)来的高,但高层(递归)却能提供更加抽象的服务,更加的简洁。
从个人来讲,我非常认同“迭代是人,递归是神”!
编程中,循环、迭代、遍历和递归之间的区别
循环(loop) - 最基础的概念, 所有重复的行为
递归(recursion) - 在函数内调用自身, 将复杂情况逐步转化成基本情况
(数学)迭代(iterate) - 在多次循环中逐步接近结果
(编程)迭代(iterate) - 按顺序访问线性结构中的每一项
遍历(traversal) - 按规则访问非线性结构中的每一项
————————————————
版权声明:本文为CSDN博主「Never-say-Never」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mad1989/article/details/8933078
当型循环和直到型循环
当型循环:
开始循环
判断循环条件,成立
执行循环体
判断循环条件,成立
执行循环体
…
判断循环条件,这一次条件不成立
不执行循环体,直接继续往下
直到型循环:
开始循环
执行循环体
判断循环条件,成立
执行循环体
…
判断循环条件,这一次条件不成立
不执行循环体,直接继续往下
“当型”
while(i<n)
{
…..
}则说明当满足条件i<n时执行{ }中代码;
“直到型”
do
{
} while(i<n)
则说明先执行{ }中代码,再判断是否是i<n;
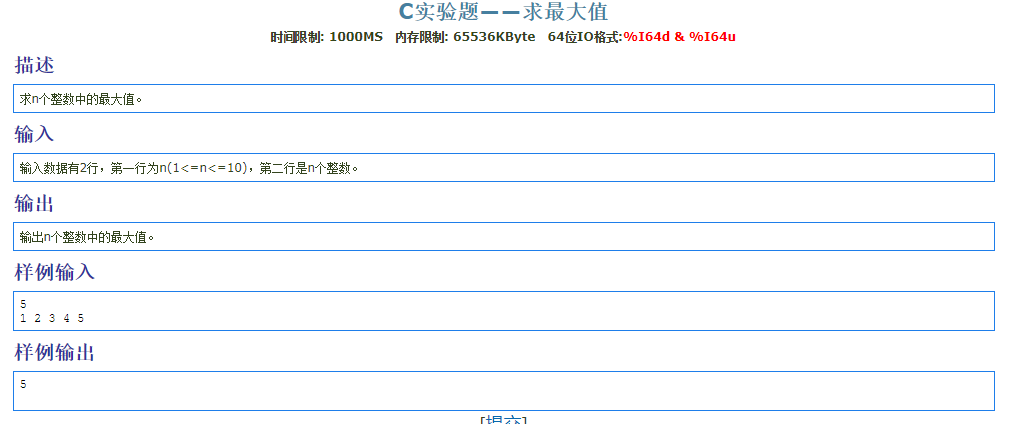
1 |
|
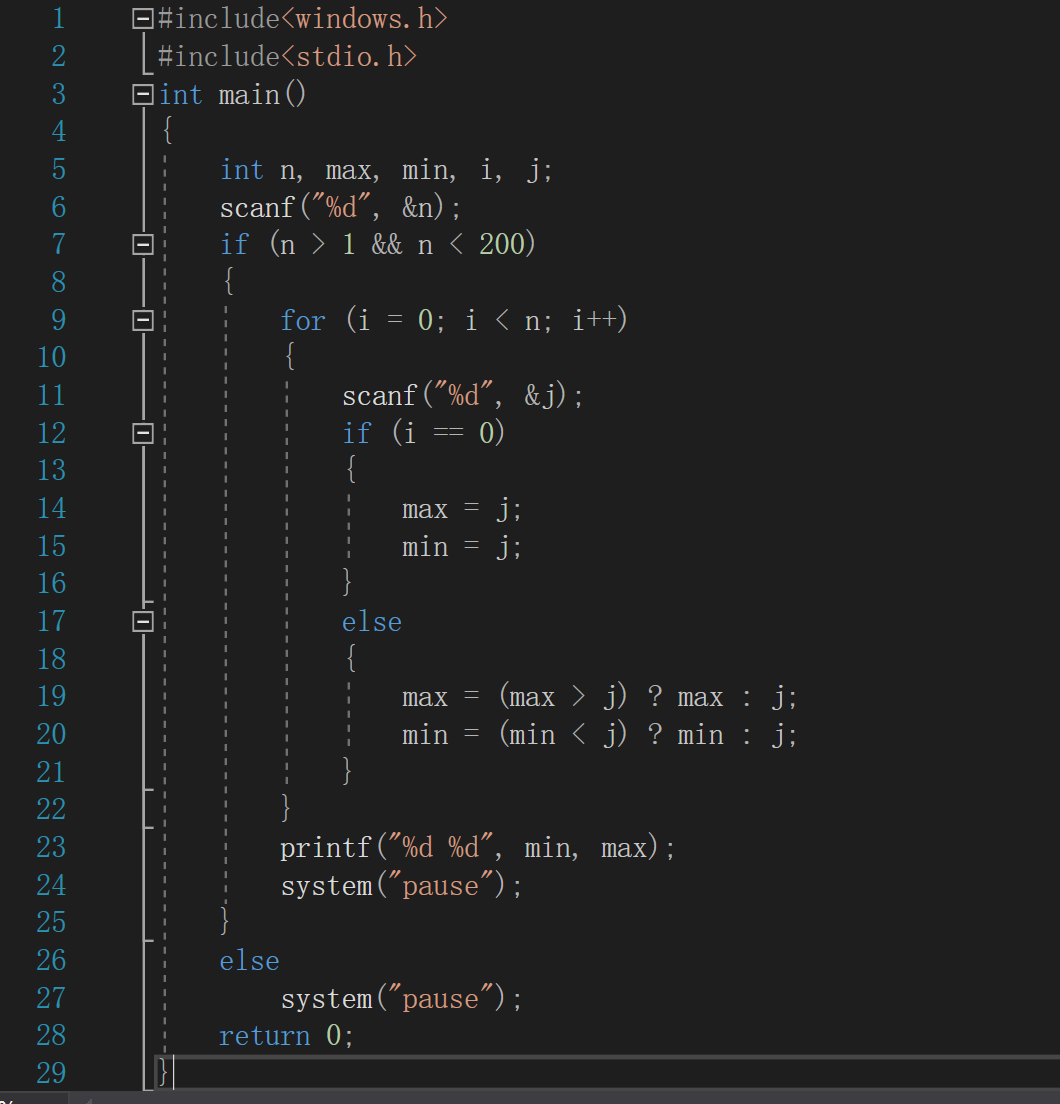
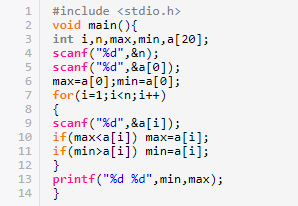
比较 输出 最大最小值
8.加强一重循环
https://blog.csdn.net/S1259364843/article/details/92420371
C语言求最小公倍数和最大公约数三种算法(经典)

1 |
|

1 |
|
1 |
|
1 |
|
素数:除了1和它自己之外,不能被其他数整除的数。
以下用三种方法解答:
https://blog.csdn.net/yuemeicheng/article/details/81185154

1 |
|
1 |
|
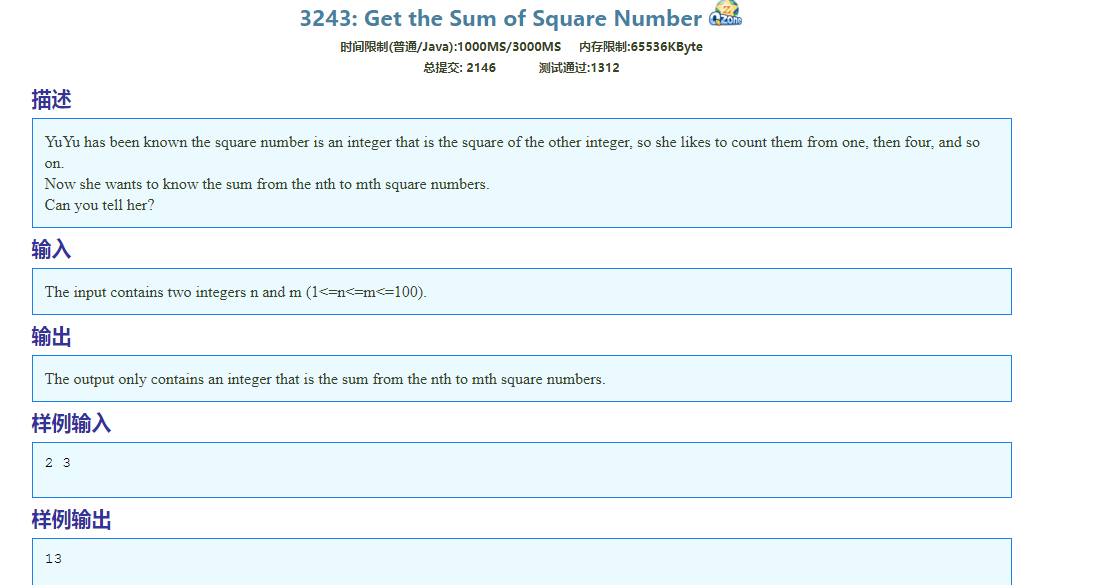
1 |
|
9.多组数据格式
EOF的意义及用法(while(scanf(“%d”,&n) != EOF))
https://blog.csdn.net/wangzhen199009/article/details/8781152
EOF,为End Of File的缩写,通常在文本的最后存在此字符表示资料结束。
在微软的DOS和Windows中,读取数据时终端不会产生EOF。此时,应用程序知道数据源是一个终端(或者其它“字符设备”),并将一个已知的保留的字符或序列解释为文件结束的指明;最普遍地说,它是ASCII码中的替换字符(Control-Z,代码26)。
在C语言中,或更精确地说成C标准函数库中表示文件结束符(end of file)。在while循环中以EOF作为文件结束标志,这种以EOF作为文件结束标志的文件,必须是文本文件。在文本文件中,数据都是以字符的ASCII代码值的形式存放。我们知道,ASCII代码值的范围是0~127,不可能出现-1,因此可以用EOF作为文件结束标志。
档案存取或其它 I/O 功能可能传回等于象征符号值 (巨集) EOF 指示档案结束的情形发生。实际上 EOF 的值通常为 -1,但它依系统有所不同。巨集 EOF会在编译原始码前展开实际值给预处理器。
C语言中,EOF常被作为文件结束的标志。还有很多文件处理函数处错误后的返回值也是EOF,因此常被用来判断调用一个函数是否成功。
例如:
#include <stdio.h>
int main(){
int n;
while(scanf(“%d”,&n) != EOF){
}
return 0;
}
当上面的程序运行时,如果不加” != EOF”,那么这个程序就是个死循环,会一直运行下去;加上” != EOF”后该程序就不是死循环了,如果在终端不进行输入该程序会自动结束(while的意思就是说当当前输入缓存还有东西时就一直读取,直到输入缓存中的内容为空时停止)。
在这”scanf(“%d”,&n) != EOF”相当于”scanf(“%d”,&n) != EOF”,或”~scanf(“%d”,&n)”,或”scanf(“%d”,&n) == 1 “ 。scanf的返回值由后面的参数决定
scanf(“%d%d”, &a, &b);
如果a和b都被成功读入,那么scanf的返回值就是2;如果只有a被成功读入,返回值为1;如果a和b都未被成功读入,返回值为0;如果遇到错误或遇到end of file,返回值为EOF,且返回值为int型。
但是在C++中不存在这种用法,但相同作用的有while((cin >> a) != 0):
以前不理解在while里面用cin >> a;是什么意思,cin是C++的输入流对象,”>>”是重载的运算符,cin>>的返回值是cin对象。用这个当条件的话,通过检测其流的状态来判断结束;
(1)若流是有效的,即流未遇到错误,那么检测成功;
(2)若遇到文件结束符,或遇到一个无效的输入时(例如本题输入的值不是一个整数),istream对象的状态会变为无效,条件就为假;读取失败的时候,就不能继续读取了,那么读取操作结束,while(cin>>a)就返回false,跳出循环!
C++中的while (cin>>n,n):
他的作用是:输入一个数,这数不为0时进入循环,为0时跳出循环。
采纳:”https://www.cnblogs.com/tgycoder/p/4958519.html"
输入(cin)缓冲是行缓冲。当从键盘上输入一串字符并按回车后,这些字符会首先被送到输入缓冲区中存储。每当按下回车键后,cin 就会检测输入缓冲区中是否有了可读的数据,这种情况下cin对键盘上是否有作为流结束标志CTRL+Z或者CTRL+D,其检查的方式有两种:阻塞式以及非阻塞式。
阻塞式检查方式指的是只有在回车键按下之后才对此前是否有 Ctrl+Z 组合键按下进行检查,非阻塞式样指的是按下 Ctrl+D 之后立即响应的方式。如果在按 Ctrl+D 之前已经从键盘输入了字符,则 Ctrl+D的作用就相当于回车,即把这些字符送到输入缓冲区供读取使用,此时Ctrl+D不再起流结束符的作用。如果按 Ctrl+D 之前没有任何键盘输入,则 Ctrl+D 就是流结束的信号。
阻塞式的方式有一个特点:只有按下回车之后才有可能检测在此之前是否有Ctrl+Z按下。
————————————————
版权声明:本文为CSDN博主「一个奔跑的C」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/henu1710252658/article/details/83040281

1 |
|

1 | C |

1 |
|
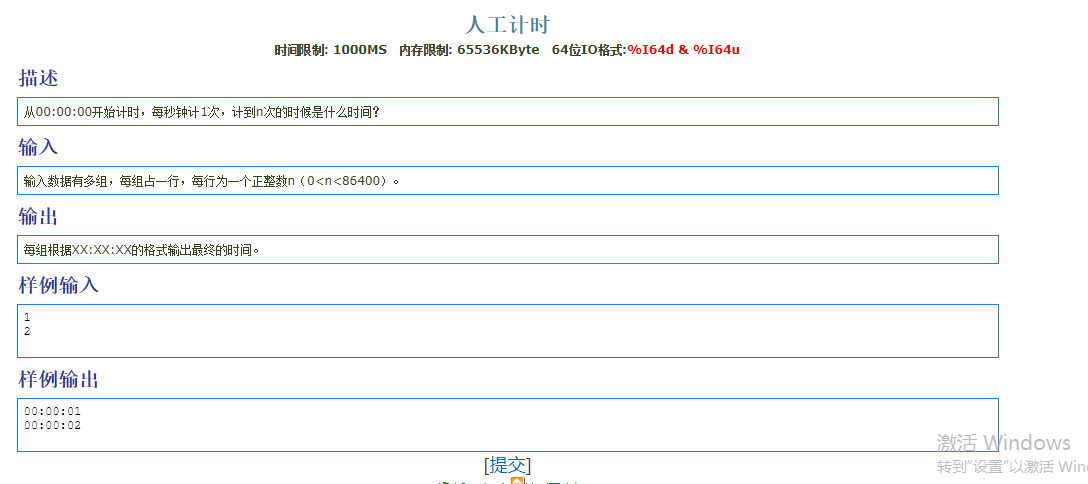
1 |
|

1 |
|
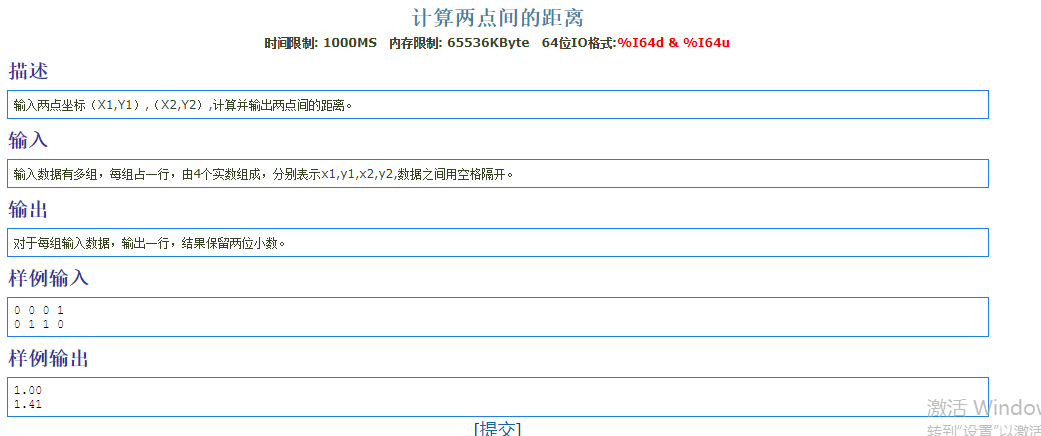
1 |
|
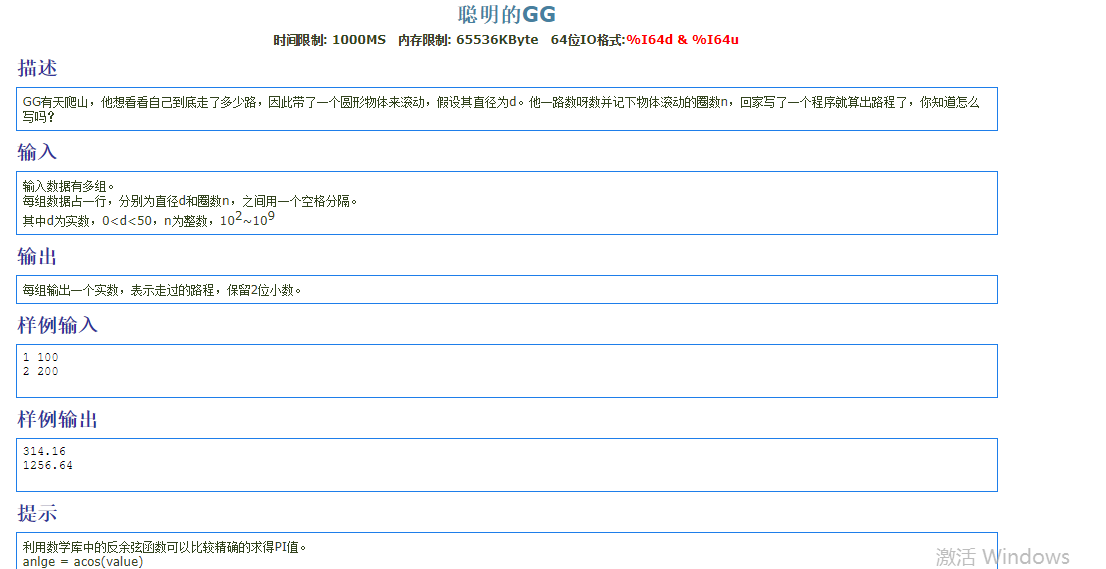
1 | C |
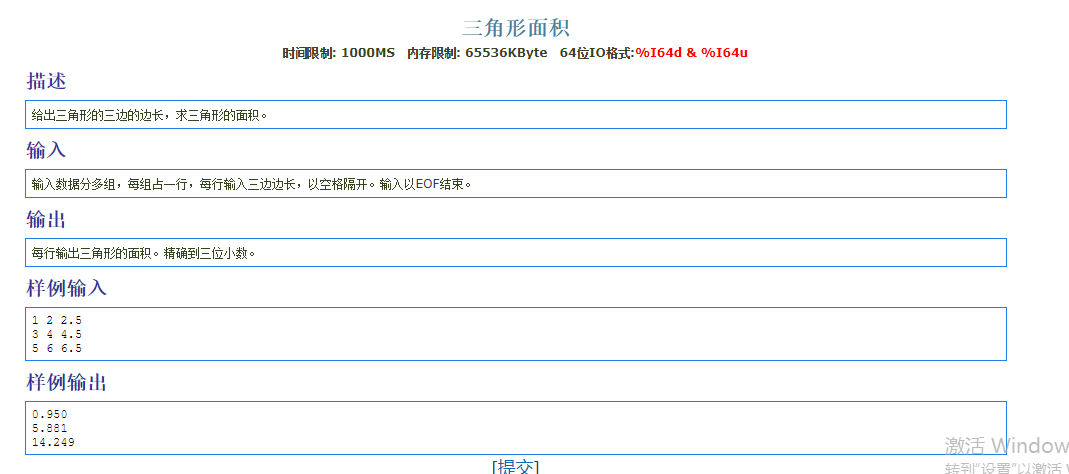
1 |
|

1 |
|
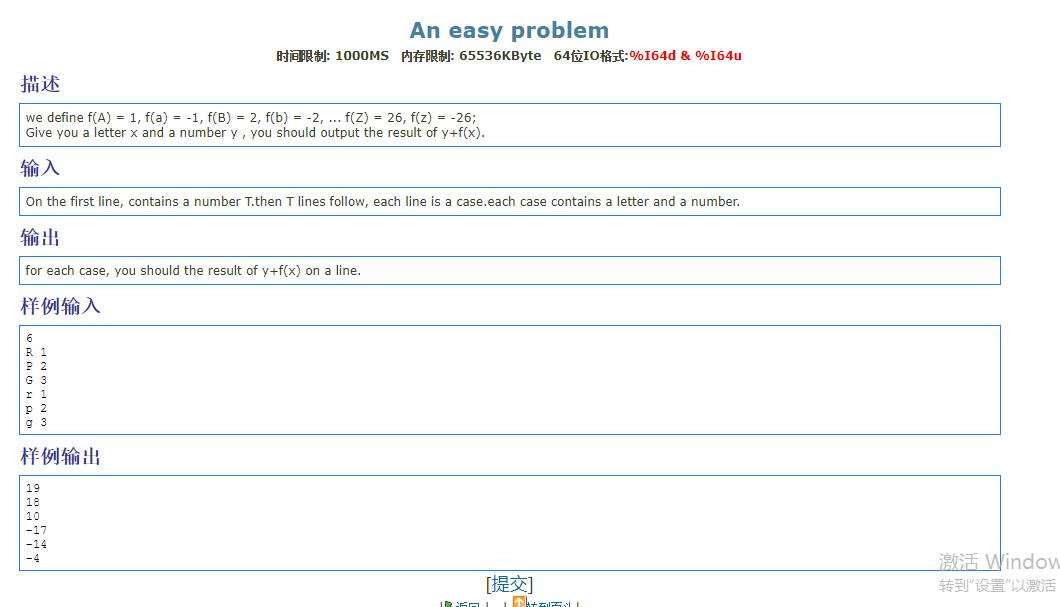
1 | 解题思路: |
1 |
|
10.多组数据&选择结构
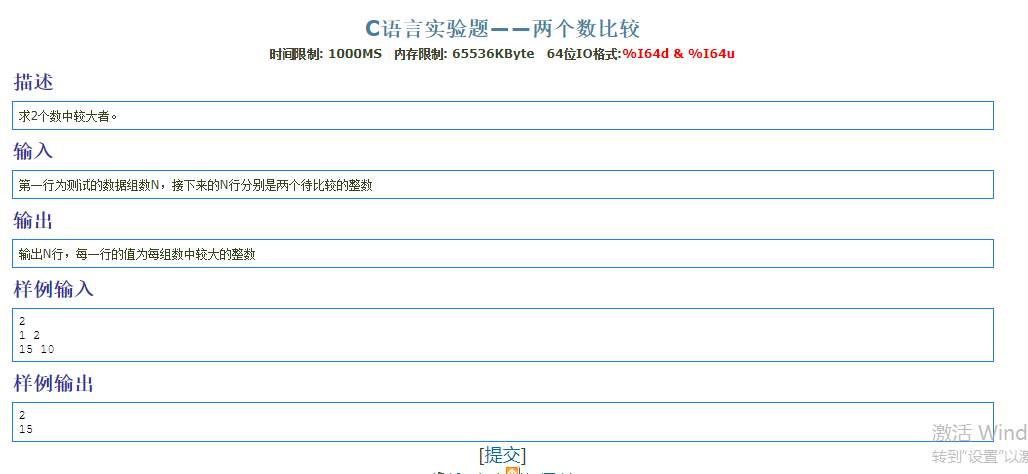
1 |
|
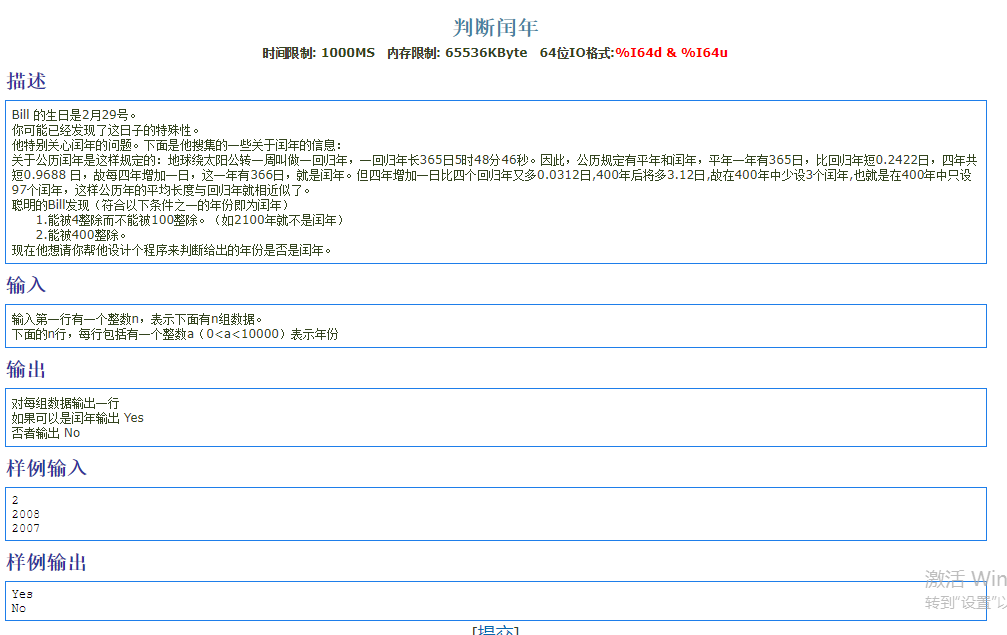
1 |
|
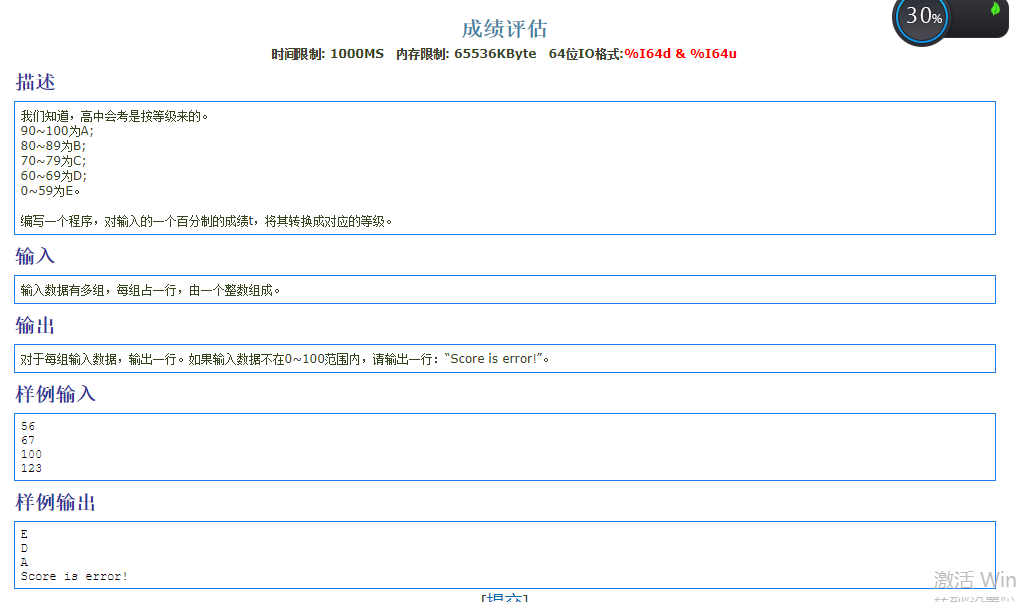
1 |
|

1 |
|
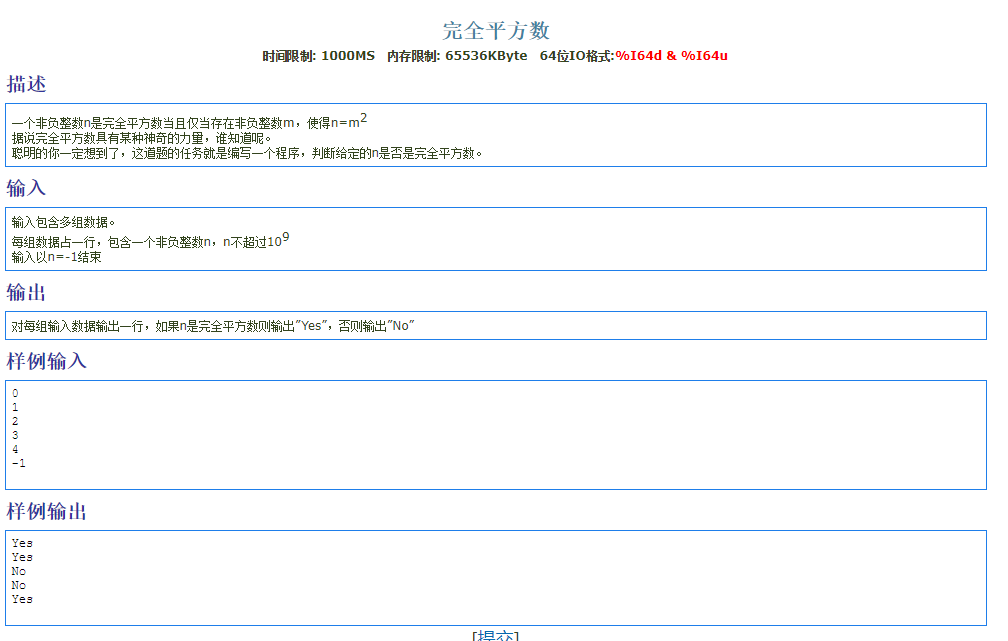
1 |
|
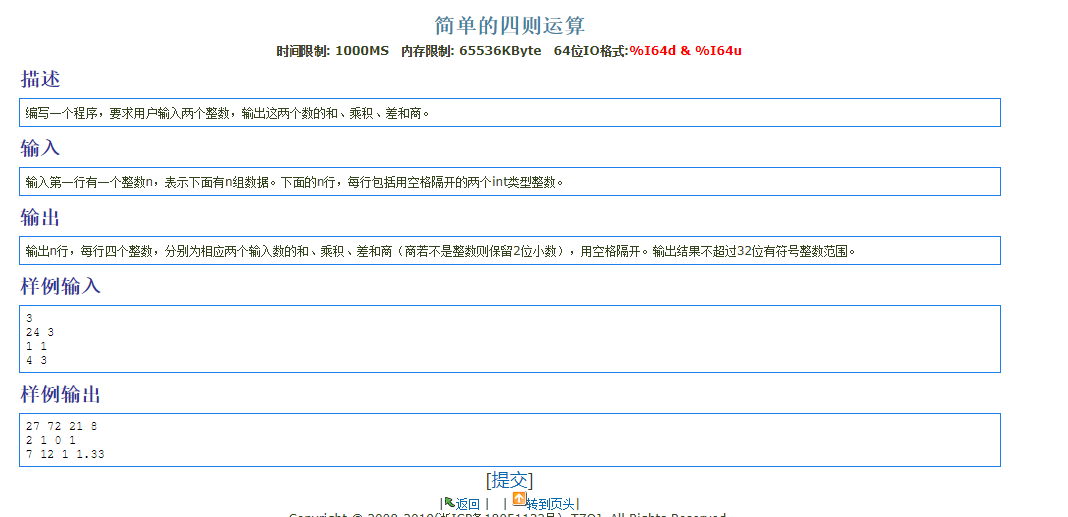
#include
#include
using namespace std;
class tr
{private:
int a,b,c,k,s,d;
double h;
public:
void iutput();
void chuli();
void output();
};
int main()
{ int n,i;
tr tr[1000];
cin>>n;
for(i=0;i<n;i++)
{ tr[i].iutput();
tr[i].chuli();
}
return 0;
}
void tr::iutput()
{
cin>>a>>b;
}
void tr::chuli()
{ s=a+b;
d=a-b;
k=ab;
if(a%b==0)
cout<<s<<’ ‘<<k<<’ ‘<<d<<’ ‘<<a/b<<endl;
else
cout<<s<<’ ‘<<k<<’ ‘<<d<<’ ‘<<setiosflags(ios::fixed)<<setprecision(2)<<a/(b1.00)<<endl;
}

